Big Data = Big Insights? Operationalising Brooks' Law in a Massive GitHub Data Set
Christoph Gote, Pavlin Mavrodiev, Frank Schweitzer and Ingo Scholtes
2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE) (2022)
Research: Data Science Software Engineering
Abstract
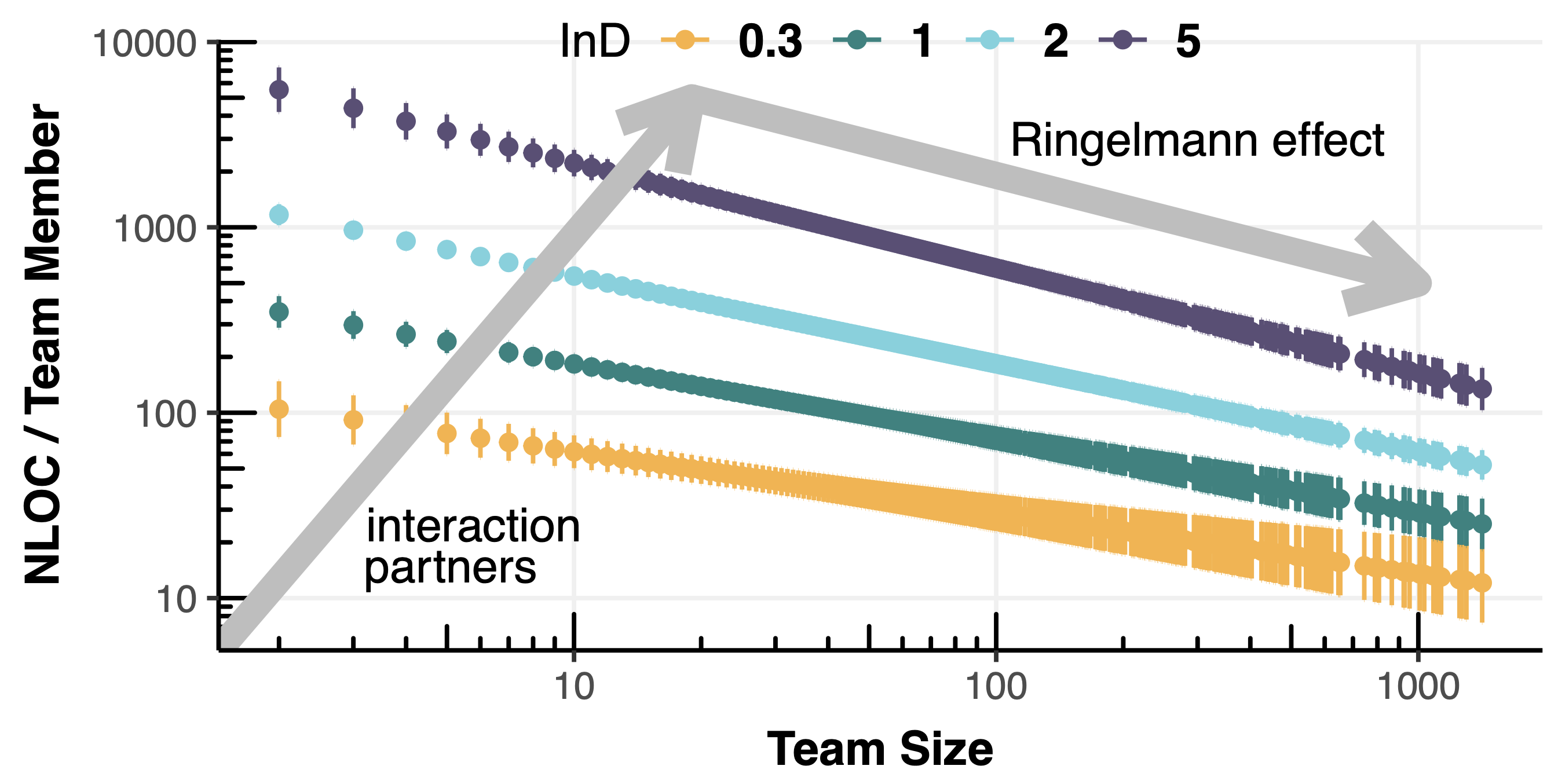
Massive data from software repositories and collaboration tools are widely used to study social aspects in software development. One question that several recent works have addressed is how a software project's size and structure influence team productivity, a question famously considered in Brooks' law. Recent studies using massive repository data suggest that developers in larger teams tend to be less productive than smaller teams. Despite using similar methods and data, other studies argue for a positive linear or even super-linear relationship between team size and productivity, thus contesting the view of software economics that software projects are diseconomies of scale. In our work, we study challenges that can explain the disagreement between recent studies of developer productivity in massive repository data. We further provide, to the best of our knowledge, the largest, curated corpus of GitHub projects tailored to investigate the influence of team size and collaboration patterns on individual and collective productivity. Our work contributes to the ongoing discussion on the choice of productivity metrics in the operationalisation of hypotheses about determinants of successful software projects. It further highlights general pitfalls in big data analysis and shows that the use of bigger data sets does not automatically lead to more reliable insights.