Data-driven modeling of collaboration networks: A cross-domain analysis
Mario Vincenzo Tomasello, Giacomo Vaccario and Frank Schweitzer
EPJ Data Sci. (2017)
Research: R&D Collaborations Science of Science
Abstract
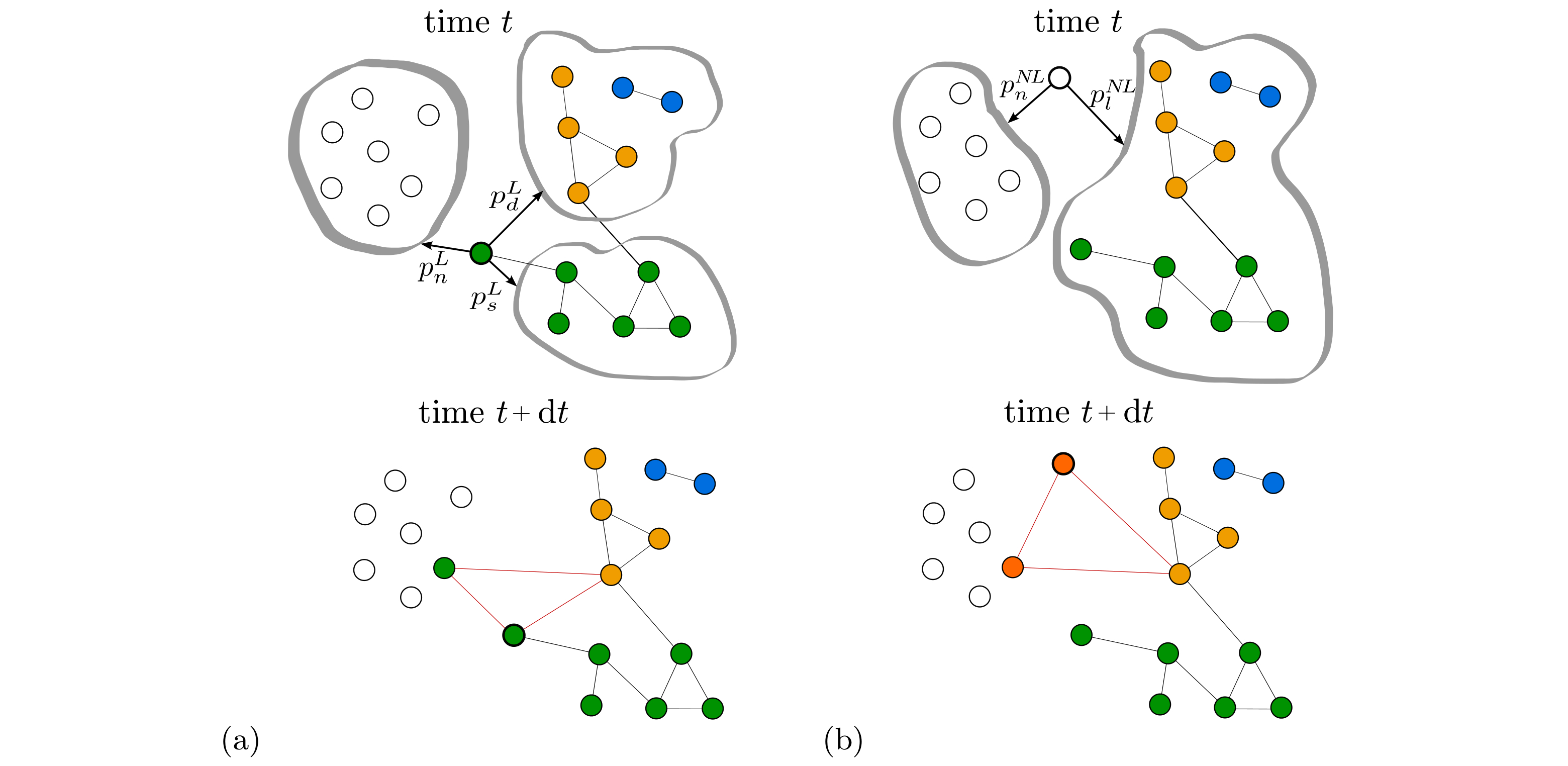
We analyze large-scale data sets about collaborations from two different domains: economics, specifically 22.000 R&D alliances between 14.500 firms, and science, specifically 300.000 co-authorship relations between 95.000 scientists. Considering the different domains of the data sets, we address two questions: (a) to what extent do the collaboration networks reconstructed from the data share common structural features, and (b) can their structure be reproduced by the same agent-based model. In our data-driven modeling approach we use aggregated network data to calibrate the probabilities at which agents establish collaborations with either newcomers or established agents. The model is then validated by its ability to reproduce network features not used for calibration, including distributions of degrees, path lengths, local clustering coefficients and sizes of disconnected components. Emphasis is put on comparing domains, but also sub-domains (economic sectors, scientific specializations). Interpreting the link probabilities as strategies for link formation, we find that in R&D collaborations newcomers prefer links with established agents, while in co-authorship relations newcomers prefer links with other newcomers. Our results shed new light on the long-standing question about the role of endogenous and exogenous factors (i.e., different information available to the initiator of a collaboration) in network formation.