Welcome to the
Chair of Systems Design
Welcome to the legacy webpage of the Chair of Systems Design (2004-2025).
In October 2004, Frank Schweitzer established the Chair of Systems Design at ETH Zürich. Our activities ended because of his retirement on 31 January 2025. More information can be found under Final Symposium and in an Interview on the portal of the Department of Management, Technology, and Economics.
Over a period of 20 years, more than 70 researchers from various disciplines (statistical physics, applied mathematics, computer science, political science and economics) have been working with us. 30 of them obtained their doctoral degree. More information about our collaborators can be found under Team and Theses.
Our research can be best described as data driven modelling of complex systems with particular emphasis on social, socio-technical, and socio-economic systems. More information can be found under About us, Research, Publications and Projects. The publication list will be regularly updated as pending papers are published.
Frank Schweitzer remains at ETH Zurich as a Professor emeritus (Prof. em.) and can still be reached via his email address “@ethz.ch”. A small team with Dr. Luca Verginer, Dr. Giona Casiraghi and Dr. Georges Andres will continue at ETH Zürich to work on pharmaceutical supply chain resilience.

Science Policy Forum: How malicious AI swarms can threaten democracy
The fusion of agentic AI and LLMs marks a new frontier in information warfare
added

Supply-chain vulnerabilities in critical medicines: A persistent risk to pharmaceutical security
added

Science Letter on the risks of extending U.S. tariffs to pharmaceuticals
Tariffs on low-margin generic drugs could trigger supply shocks, turning …
added

Modeling Organizational Dynamics
Master Class
added
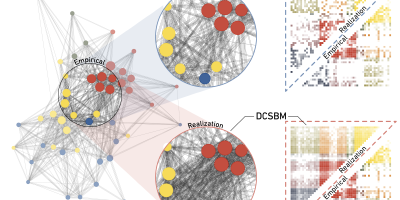
Empirical networks are sparse: Enhancing multiedge models with zero-inflation
added

Podcast on Drug Shortage Mitigation
Explore our latest research on pharmaceutical supply chain resilience in an …
added

The Complexity of Social and Economic Systems: From Models to Measures
Final Workshop Chair of Systems Design
added
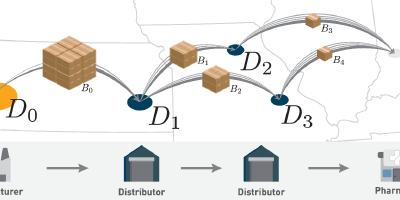
Tracing Opioids Across the US: A High-Resolution Pharmaceutical Distribution Dataset
added
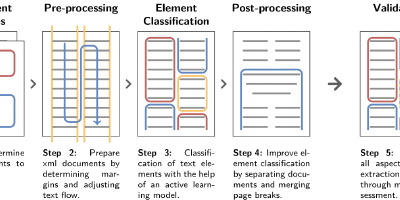
Processing Large-Scale Archival Records: The Case of the Swiss Parliamentary Records
added